오늘의 한 일
- 최종 프로젝트 - 머신러닝 모델 백엔드 완성
피부 병변 탐지 머신러닝 모델 추가
inference 앱을 새로 만들어서 진행.
inference/models.py
from django.db import models
from django_base64field.fields import Base64Field
class Inference(models.Model):
# 추론 모델 (base64 인코딩)
output_img = Base64Field(max_length=900000, blank=True, null=True)함수를 돌려서 최종적으로 나오는 이미지는 base64 포맷으로 인코딩을 거쳐 나오도록 만들었다. 펫딕셔너리 프로젝트때도 그랬는데 글자수 압박이 심하네..
시리얼라이저는 class Meta만 깔끔하게 정해줬다.. 심플하게 사용자가 이미지를 넣으면 바로 결과를 뽑아내주는 방식으로 만들고싶었기 때문에 단순단순하게
inference/utils.py
import io
import torch
from PIL import Image
import base64
import numpy as np
import cv2
def inference(input_img):
model = torch.hub.load('ultralytics/yolov5', 'custom', path='models_train/best.pt', force_reload=True) # 커스텀 학습 모델 사용
npimg = np.fromstring(input_img, np.uint8)
decode_img = cv2.imdecode(npimg, cv2.IMREAD_COLOR)
img = cv2.cvtColor(decode_img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (640, 640))
results = model(img, size=640) # inference 추론
results.ims # array of original images (as np array) passed to model for inference
results.render() # updates results.imgs with boxes and labels
for img in results.ims: # 'JpegImageFile' -> bytes-like object
buffered = io.BytesIO()
img_base64 = Image.fromarray(img)
img_base64.save(buffered, format="JPEG")
encoded_img_data = base64.b64encode(buffered.getvalue()).decode(
'utf-8') # base64 encoded image with results
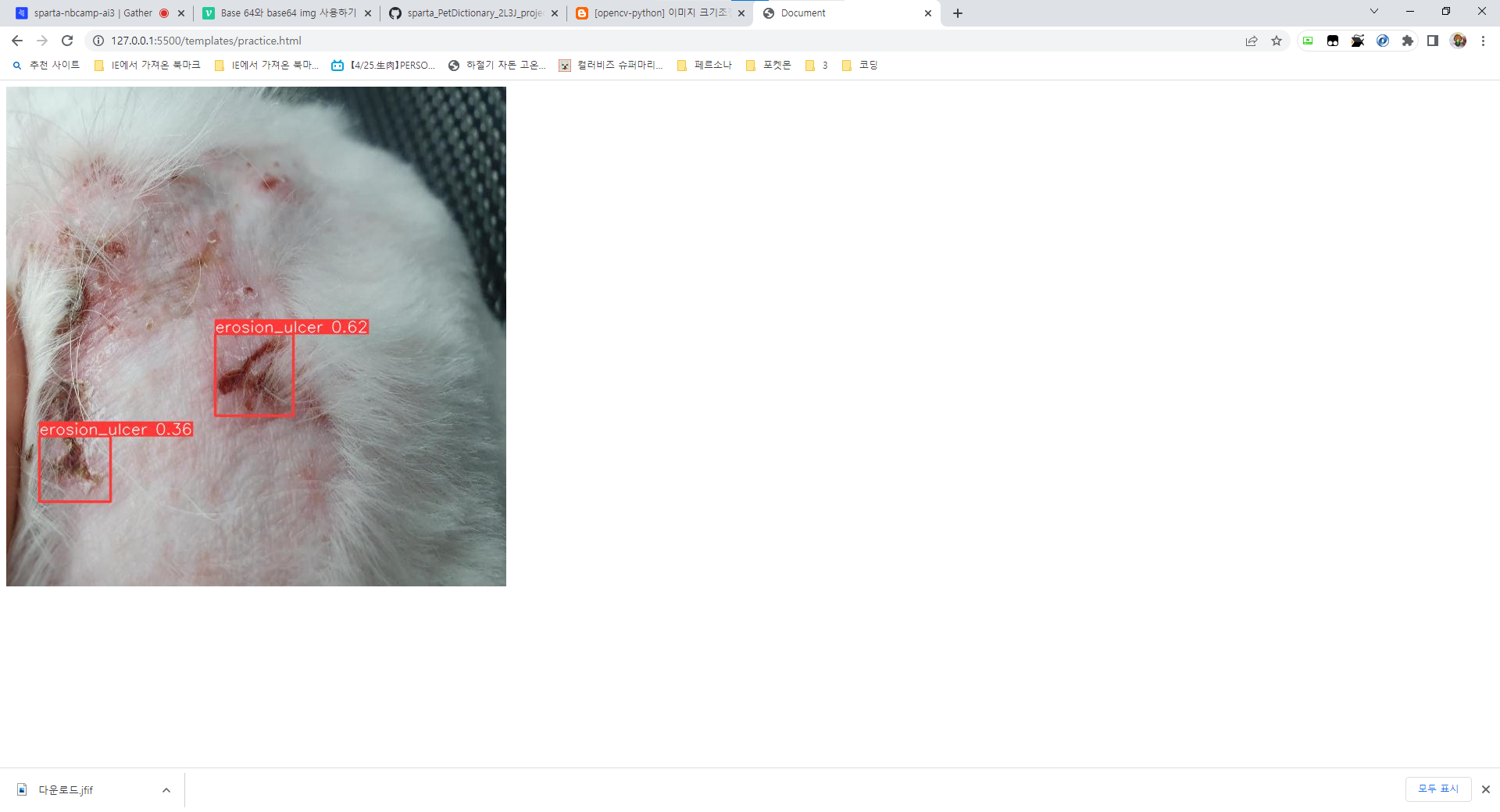
return encoded_img_dataYOLOv5 모델을 돌리는 코드, pt파일은 일단 로보플로우를 통해 라벨링처리한 미란/궤양 이미지만 적당히 학습시킨 모델을 이용했다.

json으로 라벨링 된 파일을 yolo 포맷에 맞춰 변환시키는 프로그램도 있어서 찾아봤는데 AI허브의 라벨링 데이터는 뭔가 형태가 달라서 어떻게 적용시켜야 할지 감이 안잡힌다..
덤으로 이미지 크기를 원본대로 사용하면 base64 인코딩시 글자수가 미친듯이 늘어나기때문에 640x640 크기로 리사이즈시켰다. 이미지 비율을 유지시키려면 다른방식으로 해야겠지만 일단은 뼈대만 구성해둔다는 느낌으로
inference/views.py
from rest_framework.views import APIView
from rest_framework import status
from rest_framework.response import Response
from .models import Inference as InferenceModel
from .serializers import InferenceSerializer
from .utils import inference
class InferenceView(APIView):
def get(self, request):
inference = InferenceModel.objects.latest("id")
serializer = InferenceSerializer(inference)
return Response(serializer.data, status=status.HTTP_200_OK)
def post(self, request):
data = request.data
output_img = inference(input_img=request.FILES["input_img"].read())
data = {"output_img": output_img}
serializer = InferenceSerializer(data=data)
if serializer.is_valid():
serializer.save()
return Response(serializer.data, status=status.HTTP_200_OK)
else:
return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
get 요청시에는 InferenceModel.objects.latest("id") 함수를 이용해 가장 최근의 데이터를 받아오도록 만들었다. 이러면 자기가 올린 데이터가 나올테죠..
받은 데이터는 img src 태그를 이용하여 올릴 예정.
<img src="data:image/jpeg;base64, ${output_image}">

이제 소셜로그인쪽을 진행해봐야 할 차례라서 여러 참고할만한 사이트나 저번 프로젝트때 다른 팀원분들이 시도했던 소셜로그인 부분을 둘러보았다
*참조
drf jwt 구글 소셜 로그인
[DRF] 구글 소셜로그인 (JWT)
DRF + jwt + 소셜로그인초기 환경 세팅dj-rest-auth는 업데이트가 중단된 django-rest-auth 대신 사용하는 패키지로, 회원가입과 로그인, 소셜로그인 기능을 제공해준다. 추가적으로 비밀번호 찾기/리셋,
velog.io
drf 카카오 소셜 로그인
[Django] Django REST framework(DRF) 환경에서 소셜 로그인(kakao) 구현하기 - 1)
Django 프로젝트 중에 소셜 로그인을 구현했고, 그 중 카카오 로그인에 대해 다루고자 한다. Django RE...
blog.naver.com
drf jwt 네이버 소셜 로그인
[DRF] 네이버 소셜로그인 (JWT)
네이버 개발가이드 - 네이버 로그인 연동 개발하기
velog.io
글도 찾아보고 저번 프로젝트 결과물도 살펴보니 백엔드부분은 완성하셨던거같은데 프론트엔드쪽에서 문제가 생겼던것인지 정보 연동의 문제였는지 잘 모르겠다.. 일단 직접 해보면서 경험해야할듯

카카오쪽에서 문제점이 많았다던것 같고 구글쪽은 성공했던것 같다? 코드좀 자세히 봐야겠다
트러블슈팅
거창한건 아닌데.. 아니다 거창한가..
html 파일을 구성할때 헤더, 본문, 푸터 를 지정한다면
<body>
<header>
<nav 네비게이션 바>
</nav>
</header>
<div class="content">
내용
</div>
<footer>
푸터
</footer>
</body>이렇게 될 텐데 푸터를 본문의 크기가 어떻게 되던간에 하단에 고정시키는법, 헤더 네비게이션바 상단고정 방식이 도무지 감이 잡히질 않는다.. 정보글들 참조해서 내용을 wrap으로 감싸고 wrap이고 footer고 css를 지정해줘도 푸터가 가운데에서 춤을 추는데 돌아버릴지경 ㅠㅠ