이번 주 배울것
- 다양한 신경망 구조
- 전이학습

신경망을 구성하는 방법은 정말 여러가지가 있는데요,
이 중 가장 많이 쓰이는
합성곱 신경망(CNN),
순환 신경망(RNN),
생성적 적대 신경망(GAN)에 대해 알아보겠습니다!
특히 이미지처리에서 많이 쓰이는 CNN에 대해서는 조금 더 자세히 알아보고 실습도 해볼 거예요 🙂
Convolutional Neural Networks (합성곱 신경망)
합성곱과 합성곱 신경망
- 합성곱(Convolution)은 예전부터 컴퓨터 비전(Computer Vision, CV) 분야에서 많이 쓰이는 이미지 처리 방식으로 계산하는 방식은 아래와 같습니다. 입력데이터와 필터의 각각의 요소를 서로 곱한 후 다 더하면 출력값이 됩니다.
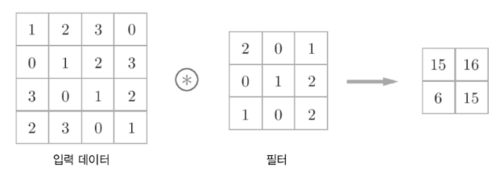
- 딥러닝 연구원들은 이 합성곱을 어떻게 딥러닝에 활용할 수 있을까 고민하다가, 1998년에 Yann LeCun 교수님이 엄청난 논문을 발표하게 됩니다.

르쿤 교수님은 합성곱을 이용한 이 신경망 디자인을 합성곱 신경망(CNN)이라고 명칭하였고 이미지 처리에서 엄청난 성능을 보이는 것을 증명했는데요. CNN의 발견 이후 딥러닝은 전성기를 이루었다고 볼 수 있습니다. 이후 CNN은 얼굴 인식, 사물 인식 등에 널리 사용되며 현재도 이미지 처리에서 가장 보편적으로 사용되는 네트워크 구조입니다.
Filter, Strides and Padding
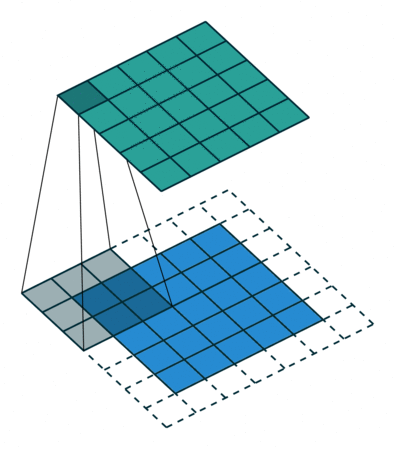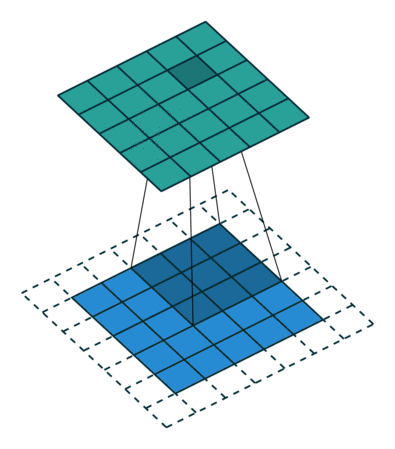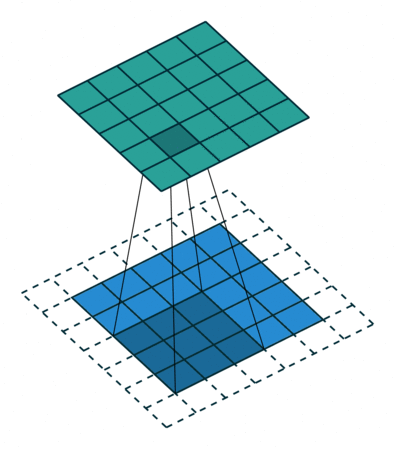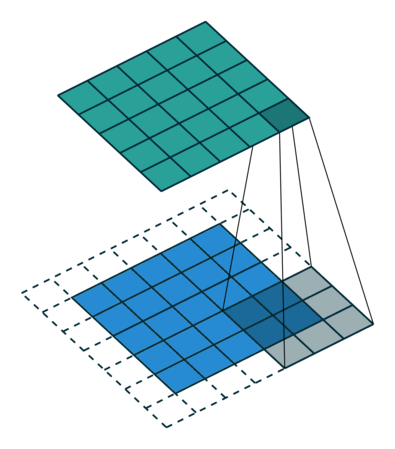
합성곱 신경망에서 가장 중요한 합성곱 계층(Convolution layer)에 대해 알아봅시다!- 아래와 같이 5x5 크기의 입력이 주어졌을 때, 3x3짜리 필터를 사용하여 합성곱을 하면 3x3 크기의 특성맵(Feature map)을 뽑아낼 수 있습니다. 필터(Filter 또는 Kernel)를 한 칸씩 오른쪽으로 움직이며 합성곱 연산을 하는데요, 이 때 이동하는 간격을 스트라이드(Stride)라고 합니다.
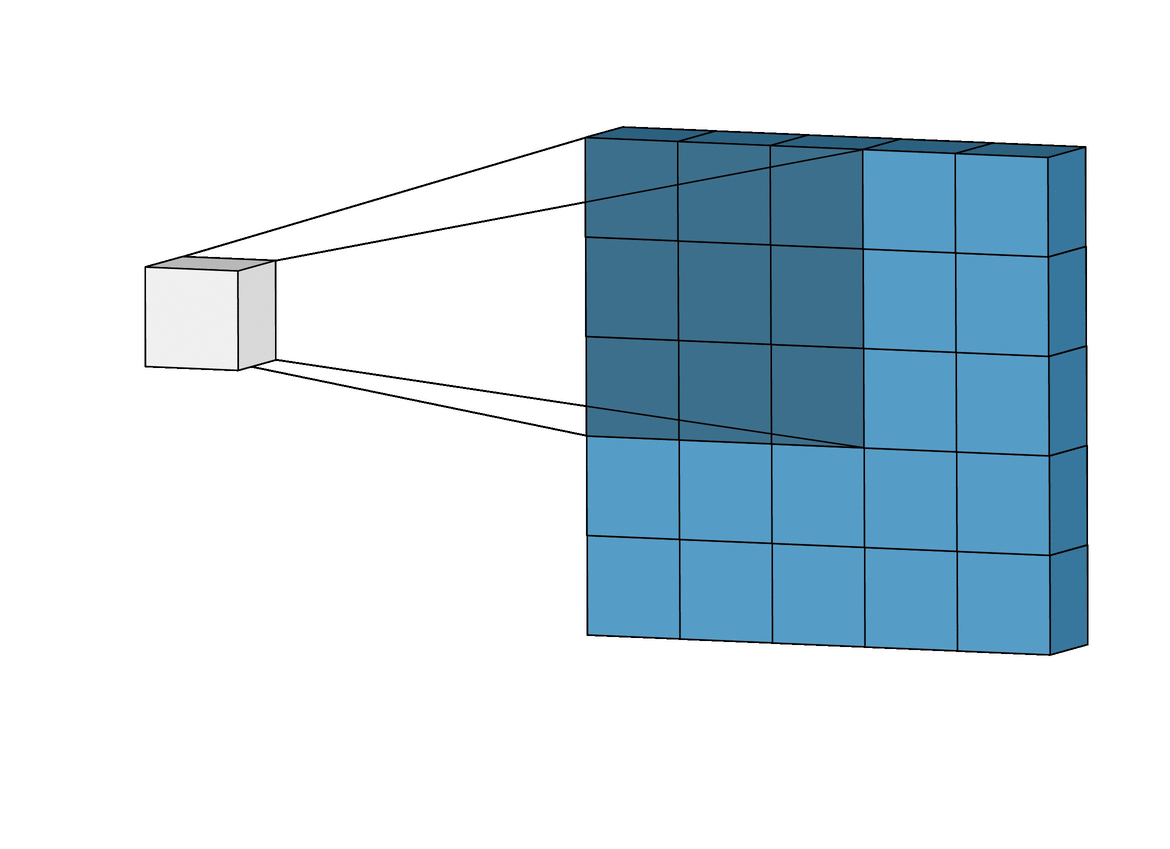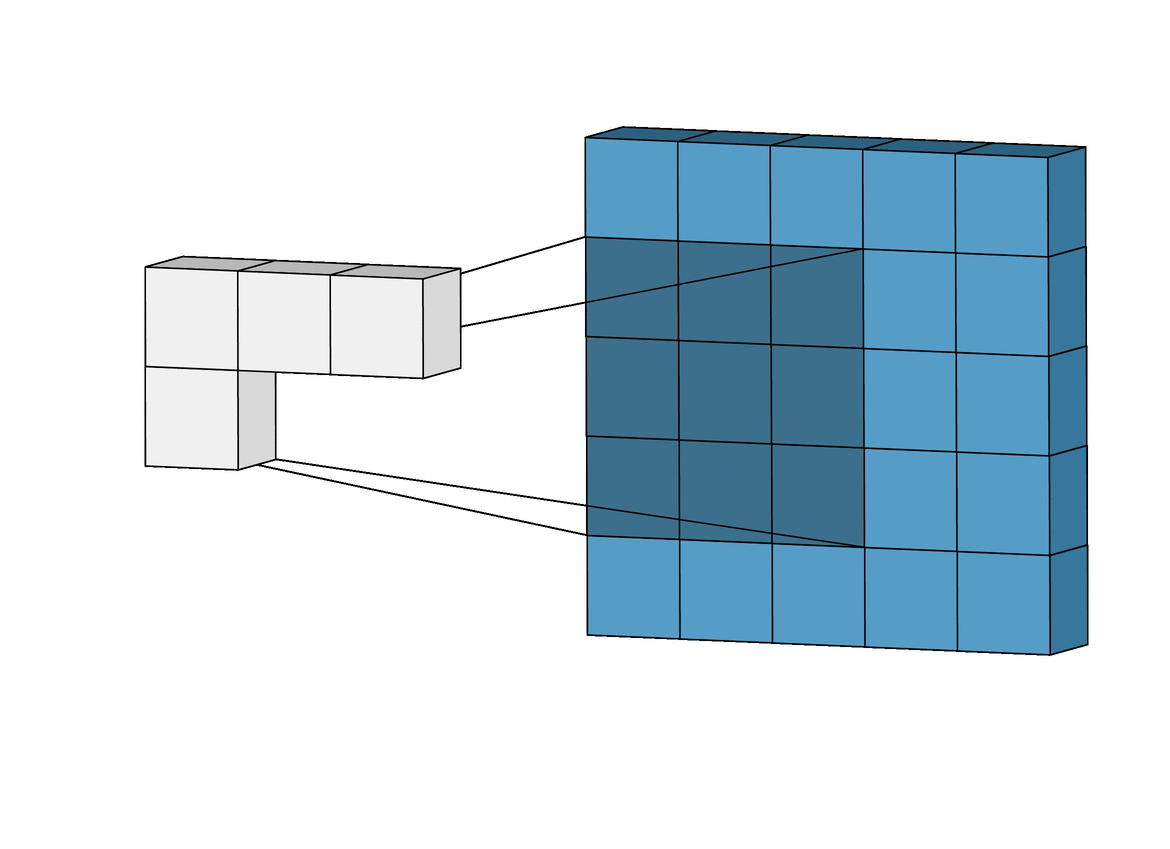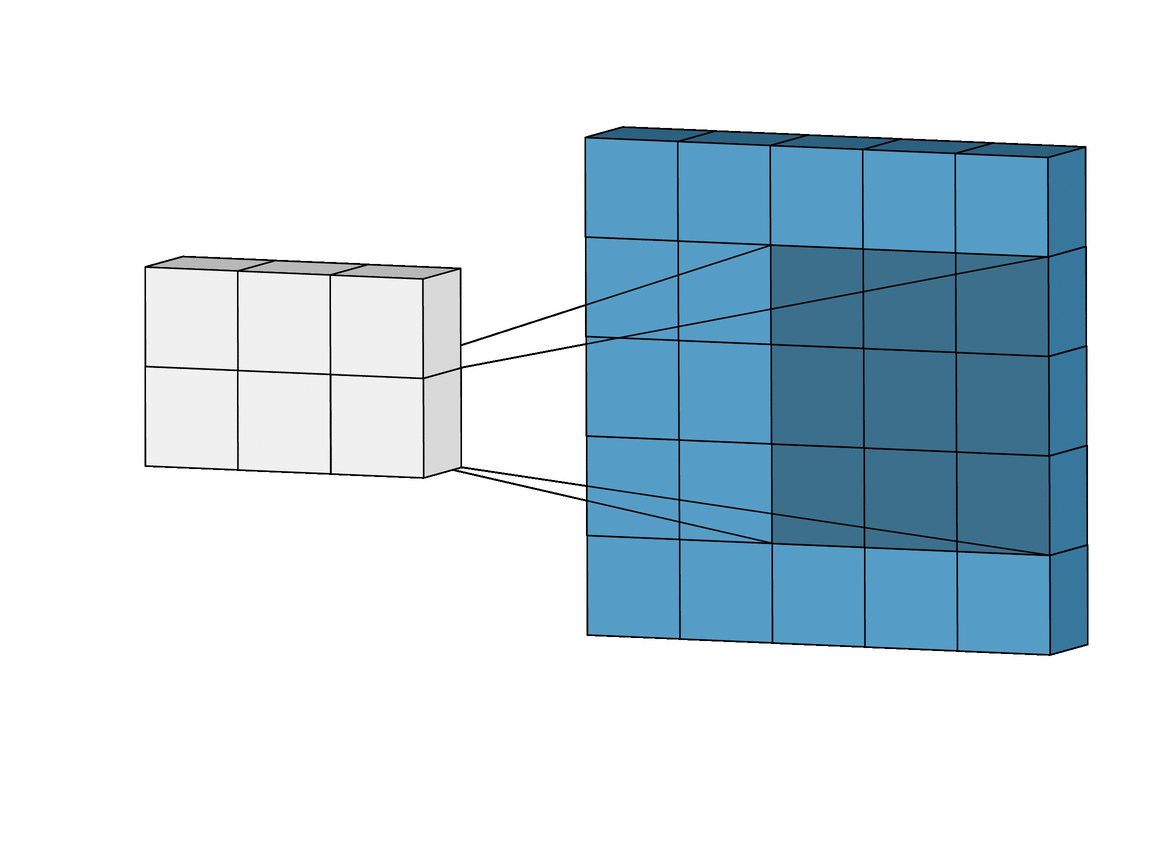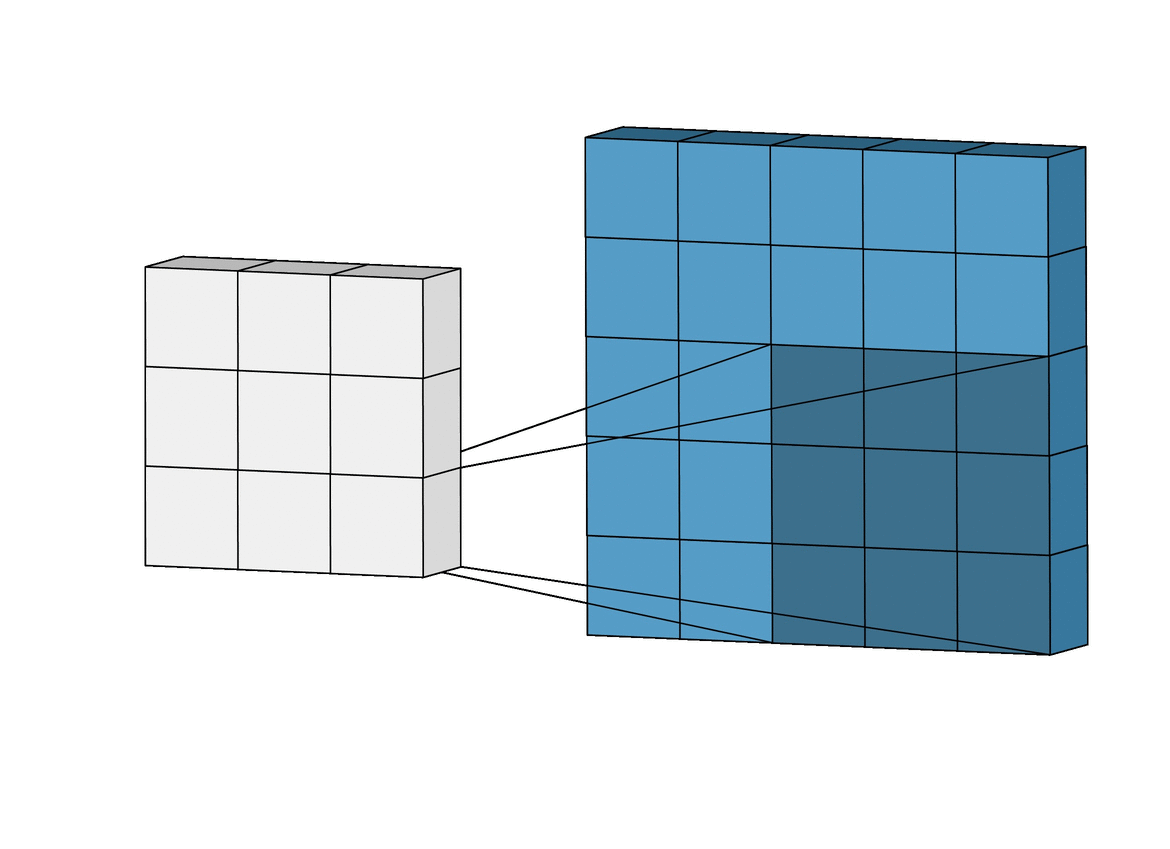
- 그런데 이렇게 연산을 하게 되면 합성곱 연산의 특성상 출력값인 특성 맵의 크기가 줄어듭니다. 이런 현상을 방지하기 위해서 우리는 패딩(Padding 또는 Margin)을 주어, 스트라이드가 1일 때 입력값과 특성 맵의 크기를 같게 만들 수 있습니다.
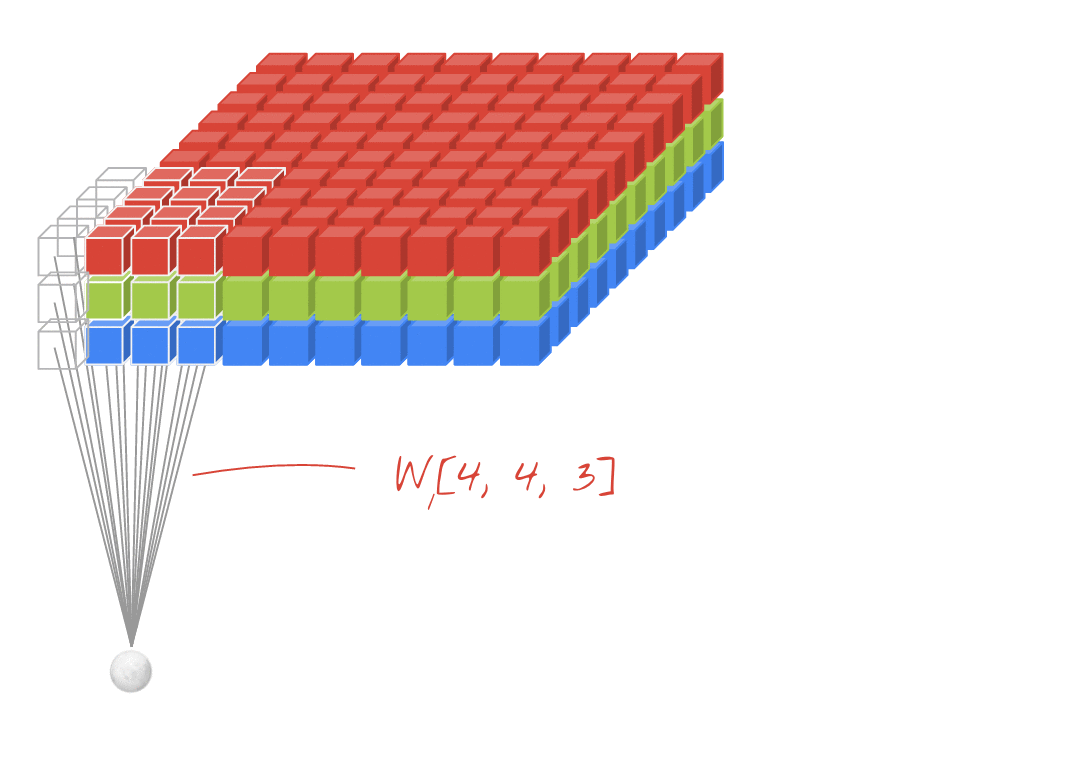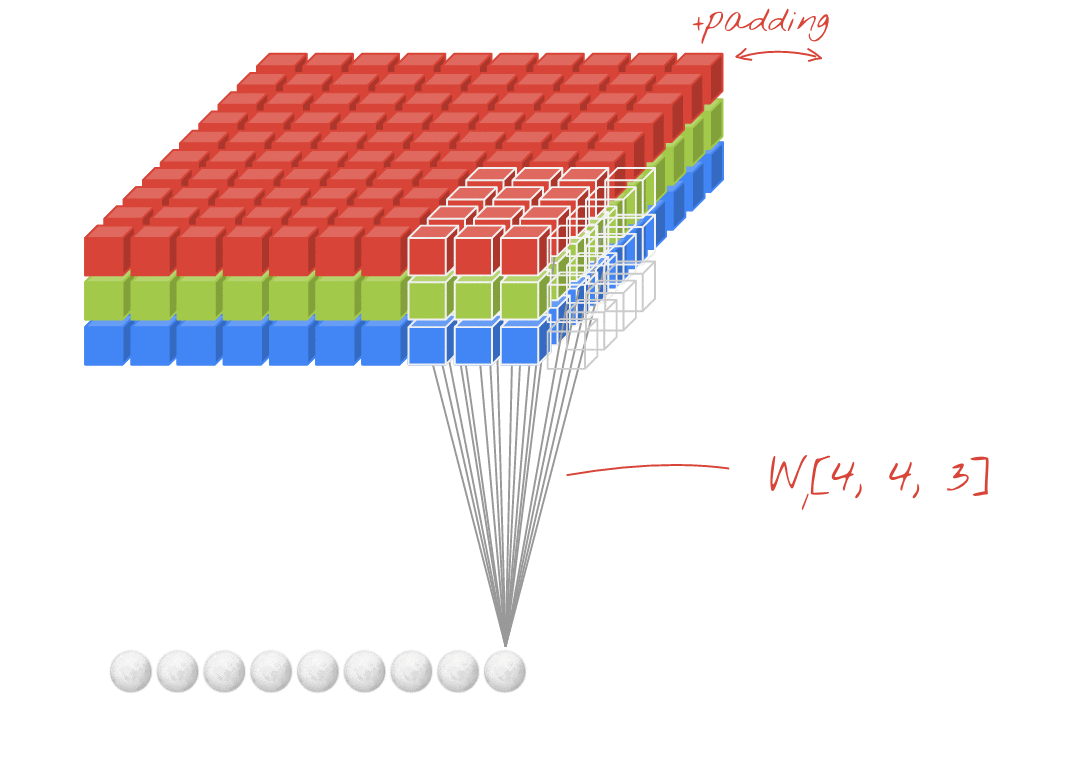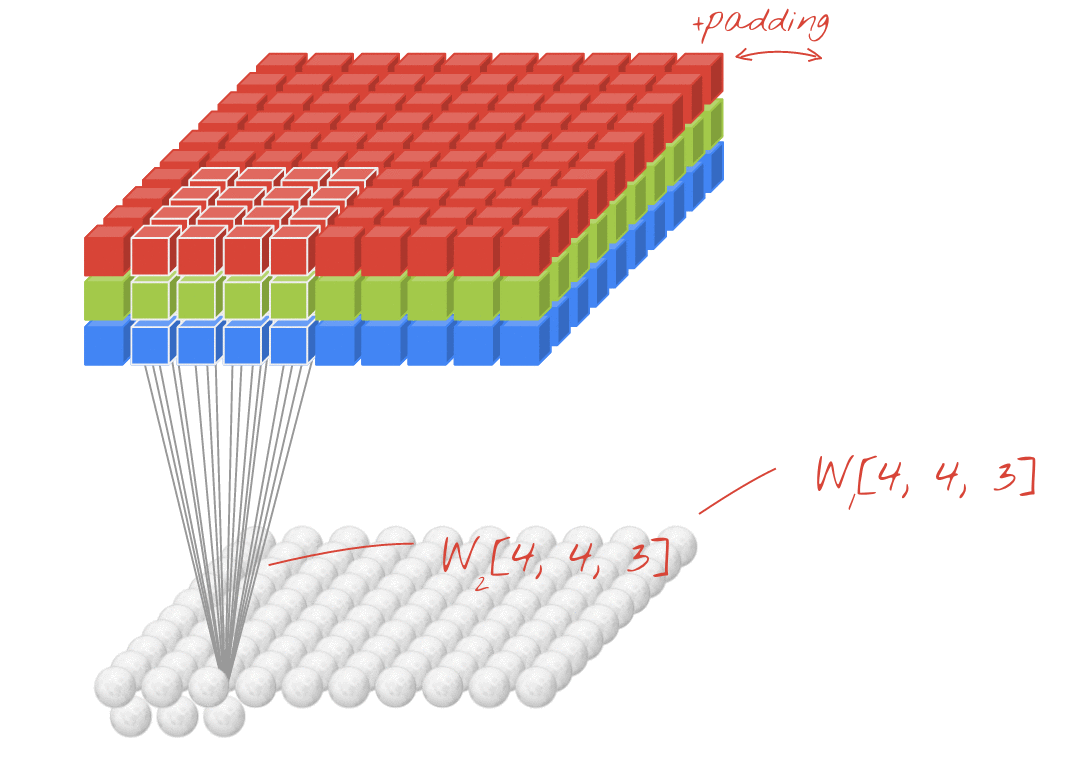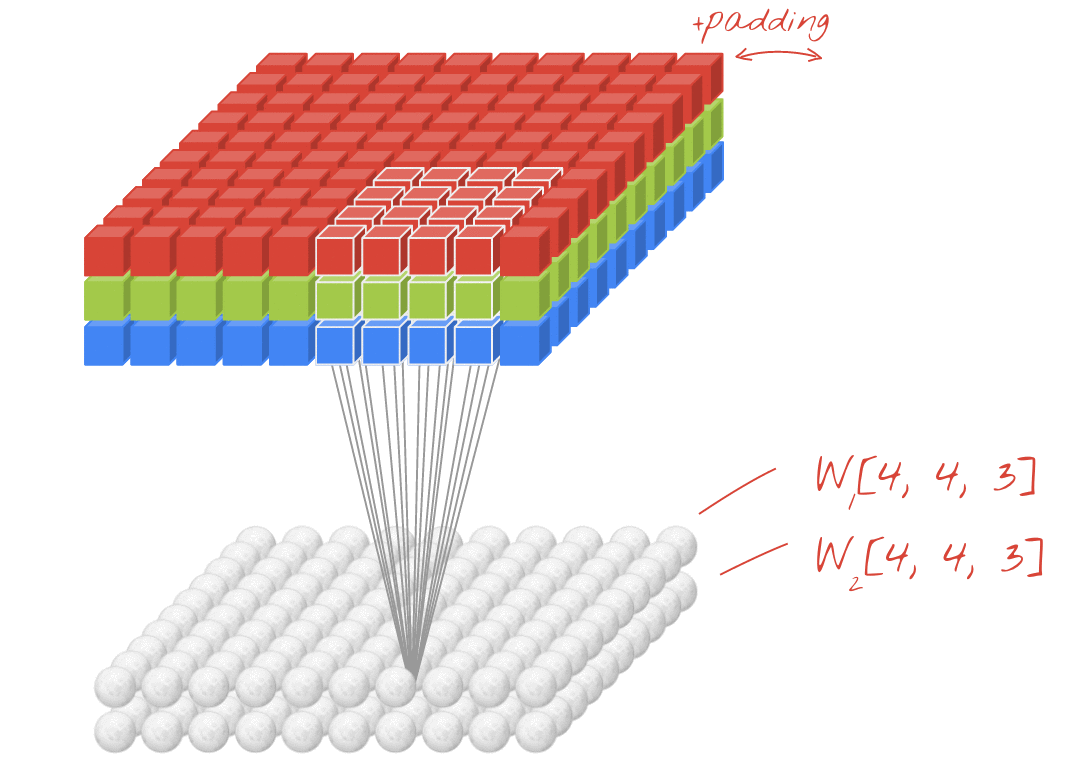
- 위에서는 1개의 필터를 사용하여 연산을 하였지만 여러개의 필터를 이용하여 합성곱 신경망의 성능을 높일 수 있습니다. 그리고 이미지는 3차원(가로, 세로, 채널)이므로 아래와 같은 모양이 됩니다. 이 그림에서 각각의 입력과 출력은 다음과 같습니다:
- 입력 이미지 크기: (10, 10, 3)
- 필터의 크기: (4, 4, 3)
- 필터의 개수 :2
- 출력 특성 맵의 크기: (10, 10, 2)
CNN의 구성
CNN의 구성
- 합성곱 신경망은 합성곱 계층(Convolution layer)과 완전연결 계층(Dense layer)을 함께 사용합니다.

- 합성곱 계층 + 활성화 함수 + 풀링을 반복하며 점점 작아지지만 핵심적인 특성들을 뽑아 내는데요. 여기서 풀링 계층(Pooling layer)은 특성 맵의 중요부분을 추출하여 저장하는 역할을 합니다.
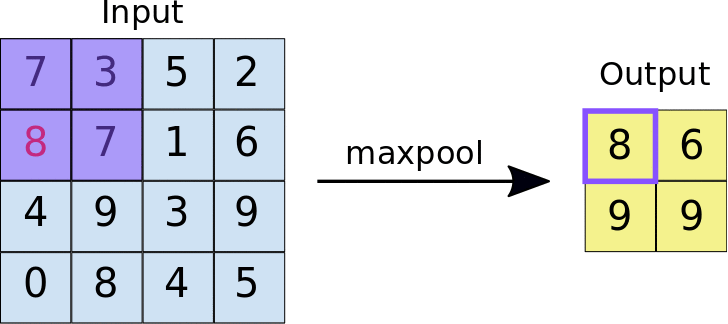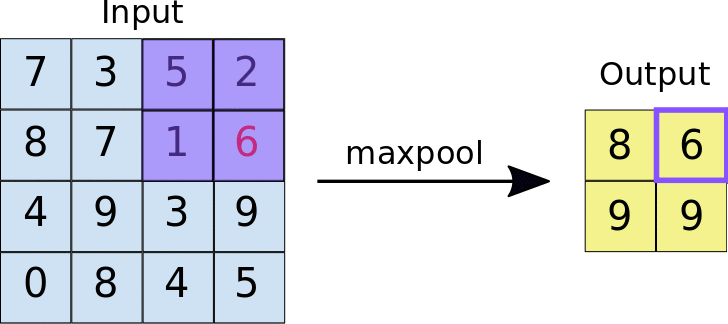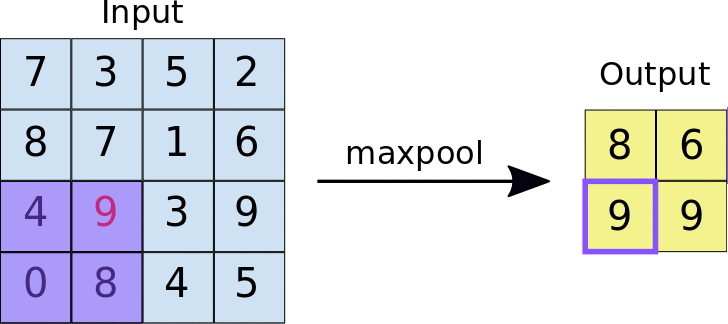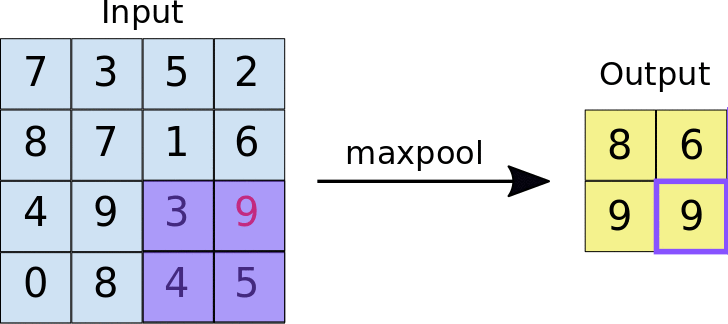
- 아래의 이미지는 Max pooling의 예시입니다. 2x2 크기의 풀 사이즈(Pool size)로 스트라이드 2의 Max pooling 계층을 통과할 경우 2x2 크기의 특성 맵에서 가장 큰 값들을 추출합니다.
- 아래는 Average pooling의 예시입니다. Max pooling에서는 2x2 크기의 특성 맵에서 최대 값을 추출했다면 Average pooling은 2x2 크기의 특성 맵에서 평균 값을 추출하는 방식입니다.

- Max pooling과 Average pooling의 결과를 비교해보면 이렇게 되겠죠?

- 다시 이 그림으로 돌아와서 두 번째 풀링 계층을 지나면 완전연결 계층과 연결이 되어야 하는데 풀링을 통과한 특성 맵은 2차원이고 완전연결 계층은 1차원이므로 연산이 불가능합니다.

- 따라서 우리는 평탄화 계층(Flatten layer)를 사용해서 2차원을 1차원으로 펼치는 작업을 하게 됩니다. 아래는 간단하게 평탄화 계층의 동작을 설명한 그림입니다.
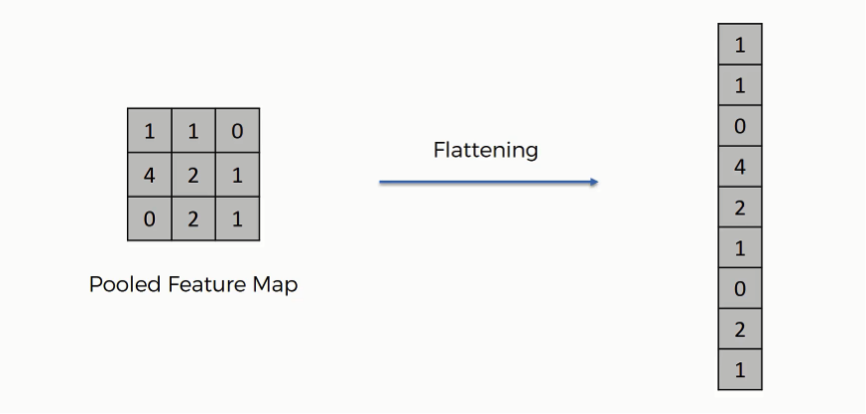
- 평탄화 계층을 통과하게 되면 우리는 완전연결 계층에서 행렬 곱셈을 할 수 있게되고 마찬가지로 완전연결 계층(=Dense=Fully connected) + 활성화 함수의 반복을 통해 점점 노드의 개수를 축소시키다가 마지막에 Softmax 활성화 함수를 통과하고 출력층으로 결과를 출력하게 됩니다.
CNN의 활용 예
컴퓨터 비전에서 필요한 기본 기능
- 물체 인식(Object Detection)

Object detection은 사진 이미지에서 정확히 물체를 인식하는 것을 뜻하며 컴퓨터비전에서 가장 중요한 기술입니다. 각각의 객체를 정확하게 인식하는 것부터 Computer Vision이 시작하기 때문입니다.
핸드폰 카메라 셀카 모드에서 얼굴 영역을 자동으로 찾아주는 것도 object detection이라고 할 수 있겠죠?
- YOLO (You Only Look Once) ※ 이번 프로젝트에 쓰일듯
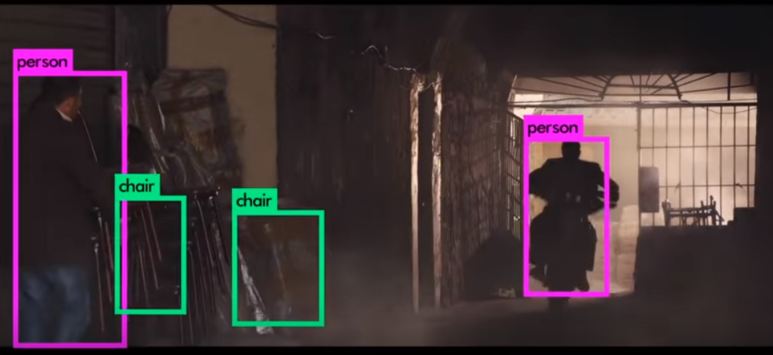
현재 V5까지 나왔으며 속도가 빠르다는 강점을 가졌고 다른 real-time detection에 비해 정확도가 높아 유명한 Computer Vision 알고리즘입니다.
이미지 분할(Segmentation)

Segmentation은 각각의 오브젝트에 속한 픽셀들을 분리하는 것을 나타냅니다.
- 나누는 기준이 디테일 할수록 정교화된 성능을 가져야 하고 처리속도 또한 문제가 될 수 있습니다.
Segmentation의 Class를 동물로 분리할 수 있고, 강아지와 고양이로 분리할 수 있습니다. 더욱 더 세분화해서 분류를 하게 된다면 강아지 중에서도 웰시코기, 비숑, 진돗개로도 분리를 할 수 있습니다. - 인물과 배경을 Segmentation하여 배경은 흐릿하게 처리해서 인물을 Focus하는 기술입니다.

- 의료영상에서도, 양성/음성부분을 파악하고 악성인 부분을 Segmentation하여 인식할 수 있도록 도와줍니다.
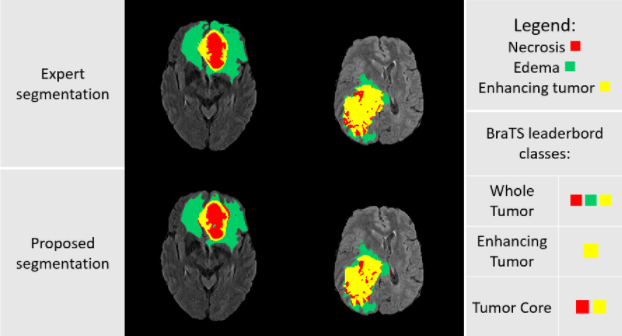
활용 예
- 자율주행 물체인식
- 자세 인식(Pose Detection)
- 화질개선(Super Resolution)
- Style Transfer
- 사진 색 복원(Colorization)
다양한 CNN 종류
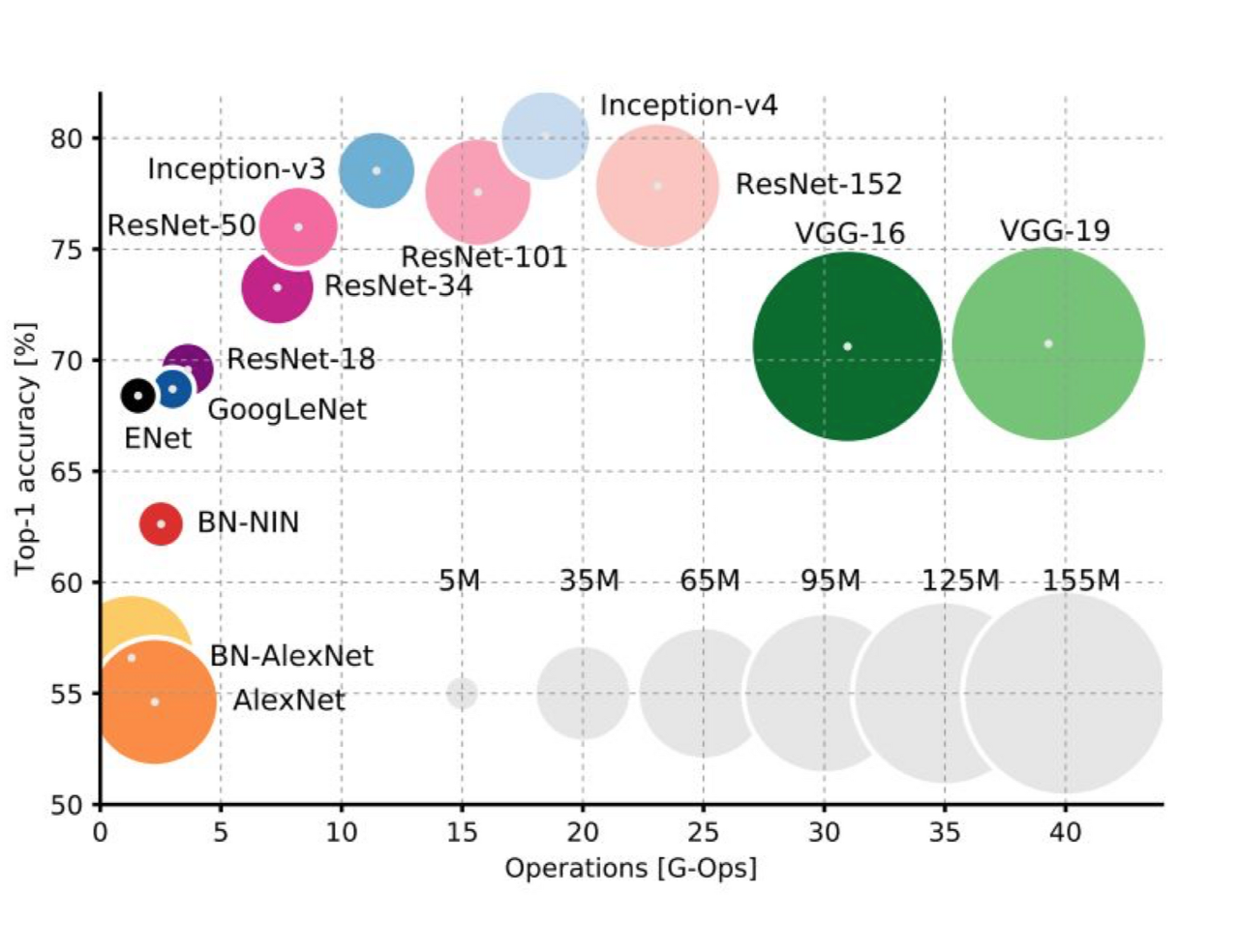
- AlexNet (2012)

컴퓨터 비전 분야의 ‘올림픽’이라 할 수 있는 ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)의 2012년 대회에서 제프리 힌튼 교수팀의 AlexNet이 Top 5 test error 기준 15.4%를 기록해 2위(26.2%)를 큰 폭으로 따돌리고 1위를 차지했습니다.
여기서 top 5 test error란 모델이 예측한 최상위 5개 클래스 가운데 정답이 없는 경우의 오류율을 나타냅니다. 당시 ILSVRC 데이터셋(Image은 1000개 범주 예측 문제였습니다. 어쨌든 AlexNet 덕분에 딥러닝, 특히 CNN이 세간의 주목을 받게 됐습니다.
AlexNet은 의미있는 성능을 낸 첫 번째 합성곱 신경망이고, Dropout과 Image augmentation 기법을 효과적으로 적용하여 딥러닝에 많은 기여를 했기 때문입니다.
- VGGNet (2014)

VGGNet은 큰 특징은 없는데 엄청 Deep한 모델(파라미터의 개수가 많고 모델의 깊이가 깊습니다)로 잘 알려져 있습니다. 또한 요즘에도 딥러닝 엔지니어들이 처음 모델을 설계할 때 전이 학습 등을 통해서 가장 먼저 테스트하는 모델이기도 하죠. 간단한 방법론으로 좋은 성적을 내서 유명해졌습니다.
- GoogLeNet(=Inception V3) (2015)
합성곱 신경망의 아버지 르쿤 교수님이 구글에서 개발한 합성곱 신경망 구조입니다. AlexNet 이후 층을 더 깊게 쌓아 성능을 높이려는 시도들이 계속되었는데, 바로 VGGNet(2014), GoogLeNet(2015) 이 대표적인 사례입니다. GoogLeNet은 VGGNet보다 구조가 복잡해 널리 쓰이진 않았지만 구조 면에서 주목을 받았습니다.
GoogLeNet 연구진들은 한 가지의 필터를 적용한 합성곱 계층을 단순히 깊게 쌓는 방법도 있지만, 하나의 계층에서도 다양한 종류의 필터, 풀링을 도입함으로써 개별 계층를 두텁게 확장시킬 수 있다는 창조적인 아이디어로 후배 연구자들에게 많은 영감을 주었습니다. 이들이 제안한 구조가 바로 Inception module (인셉션 모듈)입니다.

인셉션 모듈에서 주의깊게 보아야할 점은 차원(채널) 축소를 위한 1x1 합성곱 계층 아이디어입니다. 또한 여러 계층을 사용하여 분할하고 합치는 아이디어는, 갈림길이 생김으로써 조금 더 다양한 특성을 모델이 찾을 수 있게하고, 인공지능이 사람이 보는 것과 비슷한 구조로 볼 수 있게 합니다. 이러한 구조로 인해 VGGNet 보다 신경망이 깊어졌음에도, 사용된 파라미터는 절반 이하로 줄었습니다.
- **ResNet (2015)
AlexNet이 처음 제안된 이후로 합성곱 신경망의 계층은 점점 더 깊어졌습니다. AlexNet이 불과 5개 계층에 불과한 반면 VGGNet은 19개 계층, GoogleNet은 22개 계층에 달합니다. 하지만 층이 깊어질 수록 역전파의 기울기가 점점 사라져서 학습이 잘 되지 않는 문제(Gradient vanishing)가 발생했습니다. ResNet 저자들이 제시한 아래 학습그래프를 보면 이같은 문제가 뚜렷이 나타납니다.
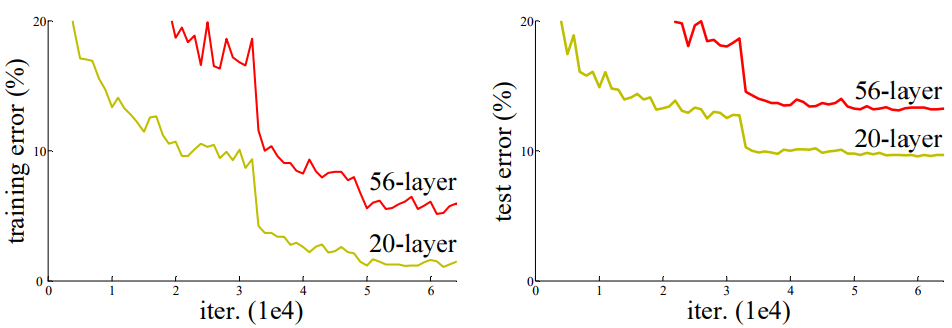
따라서 ResNet 연구진은 Residual block을 제안합니다. 그래디언트가 잘 흐를 수 있도록 일종의 지름길(Shortcut=Skip connection)을 만들어주는 방법입니다.

위의 그림에서 알 수 있듯 y = F(x) + x 를 다시 쓰면 F(x) = y - x 로 표현할 수 있고, Residual block은 입력과 출력 간의 차이를 학습하도록 설계되어 있습니다.
ResNet의 Residual block은 합성곱 신경망 역사에서 큰 영향을 끼쳤고 아직도 가장 많이 사용되는 구조 중에 하나입니다. 많은 사람들이 Residual block을 사용하면 대부분의 경우 모델의 성능이 좋아진다라고 얘기하고 있습니다.
Transfer Learning (전이 학습)
전이 학습
- 전이 학습이라는 개념은 인간이 학습하는 방법을 모사하여 만들어졌습니다. 만약 여러분들이 영어를 배워서 영어를 완벽하게 말할 수 있게 되었다고 가정합시다. 그러면 여러분이 프랑스어를 배울 때는 영어를 배울 때 사용한 지식과 방법을 사용하여 더욱 빠르게 습득할 수 있겠죠!
- 이렇게 과거에 문제를 해결하면서 축적된 경험을 토대로 그것과 유사한 문제를 해결하도록 신경망을 학습시키는 방법을 전이 학습이라고 합니다. 전이 학습은 비교적 학습 속도가 빠르고 (빠른 수렴), 더 정확하고, 상대적으로 적은 데이터셋으로 좋은 결과를 낼 수 있기 때문에 실무에서도 자주 사용하는 방법입니다.


- 전이학습은 위에서 소개한 유명한 네트워크들과 같이 미리 학습시킨 모델(pretrained models)을 가져와 새로운 데이터셋에 대해 다시 학습시키는 방법입니다. 흥미로운 점은, 꽤나 다른 형태의 데이터셋에 대해서도 효과를 보인다는 것인데요! 예를 들어, 1000개의 동물/사물을 분류하는 ImageNet이라는 대회에서 학습한 모델들을 가져와 얼굴 인식 데이터셋에 학습시켜도 좋은 결과를 얻을 수 있습니다. 이런 특징 덕분에 전이 학습은 딥러닝에서 더욱 중요해지게 되었죠!
Recurrent Neural Networks (순환 신경망)
Recurrent Neural Networks (RNN)
자연어 처리 등 다양한 분야에 활용되는 RNN에 대해 배워봅시다!- RNN은 은닉층이 순차적으로 연결되어 순환구조를 이루는 인공신경망의 한 종류입니다. 음성, 문자 등 순차적으로 등장하는 데이터 처리에 적합한 모델로 알려져 있는데요. 합성곱 신경망과 더불어 최근 들어 각광 받고 있는 신경망 구조입니다.
- 길이에 관계없이 입력과 출력을 받아들일 수 있는 구조이기 때문에 필요에 따라 다양하고 유연하게 구조를 만들 수 있다는 점이 RNN의 가장 큰 장점입니다.

- 우리가 소설을 지어내는 인공지능을 만든다고 할 때, hell 이라는 입력을 받으면 ello 라는 출력을 만들어내게 해서 결과적으로 hello 라는 순차적인 문자열을 만들어 낼 수 있게 하는 아주 좋은 구조입니다.

- 이외에도 주식이나 암호화폐의 시세를 예측한다던지, 사람과 대화하는 챗봇을 만드는 등의 다양한 모델을 만들 수 있습니다.
Generative Adversarial Network (생성적 적대 신경망)
Generative Adversarial Network (GAN)
서로 적대(Adversarial)하는 관계의 2가지 모델(생성 모델과 판별 모델)을 동시에 사용하는 기술입니다.
최근 딥러닝 학계에서 굉장히 핫한 분야입니다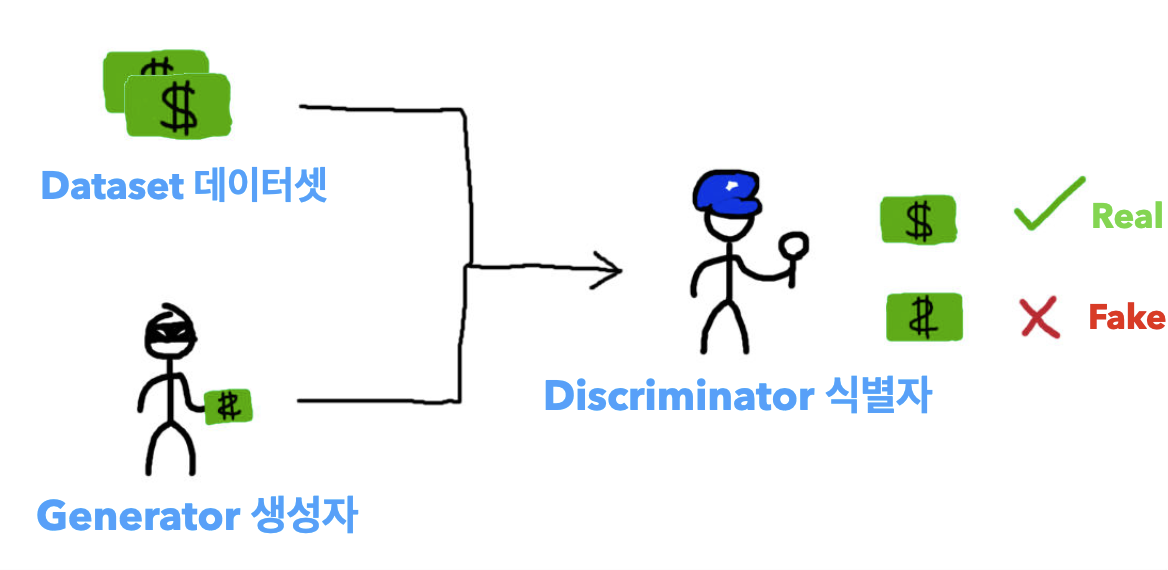
- GAN은 위조지폐범과 이를 보고 적발하는 경찰의 관계로 설명할 수 있습니다.
- 생성모델 (위조지폐범): 경찰도 구분 못하는 진짜같은 위조지폐를 만들자!
- 판별모델 (경찰): 진짜 지폐와 위조 지폐를 잘 구분해내자!
GAN이 어떻게 작용하는지 살펴보기
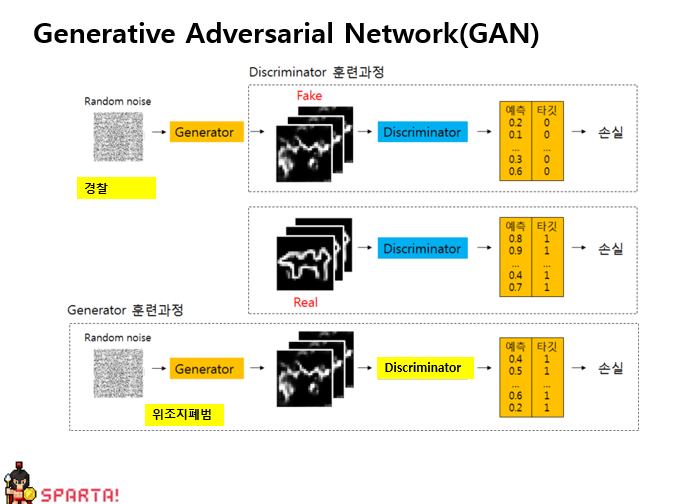
GAN에 대해 Input data와 Output data를 파악하고 위조지폐범과 경찰에 입장에서 한번 생각해보겠습니다.- AnimalGAN이라는 머신이 어떻게 잡음으로부터 동물 이미지를 만드는지 봄으로써 GAN의 작동방식을 이해해봅시다! 이 머신에게 주어진 문제는 다음과 같습니다.
- Input Data : 랜덤으로 생성된 잡음
- Output Data : 0~1 사이의 값( 0은 가짜, 1은 진짜)
- 이때 대립하는 두 모델은 다음과 같습니다.
- Generator(위조지폐범): 이미지가 진짜(1)로 판별될수록 좋겠죠? 보다 정교하게 모델을 만들려고 노력하며 Target은 1로 나오도록 해야합니다. 가짜를 진짜인 1처럼 만들기 위하여 타깃인 1과 예측의 차이인 손실을 줄이기 위하여 Backpropagation을 이용한 weight를 조정할 것입니다.
- Discriminator(경찰): 진짜 이미지는 1로, 가짜 이미지는 0으로 판별할 수 있어야합니다. 생성된 모델에서 Fake와 Real 이미지 둘다를 학습하여 예측과 타깃의 차이인 손실을 줄여야합니다.
- 이렇게 두 모델이 대립하면서(Adversarial) 발전해 에폭(Epoch)이 지날 때마다 랜덤 이미지가 점점 동물을 정교하게 생성해 내는 것(Generative)을 볼 수 있습니다.

GAN을 사용한 예시들
- CycleGAN

- StarGAN

- CartoonGAN

- DeepFake
http://www.aitimes.com/news/articleView.html?idxno=132830
삼성 AI랩이 선보인 이미지를 동영상으로 만드는 기술.
마릴린 먼로, 모나리자, 아인슈타인 등 과거 인물의 사진을 AI로 학습시켜 가상의 영상을 생성했다.
이 기술 역시 딥페이크를 기반으로 한 이미지·영상 합성이다. /유튜브 캡처
- BeautyGAN

- Toonify Yourself

CNN, 전이학습 실습
CNN 학습해보기
- 데이터셋 다운로드
- 필요한 패키지 임포트하기
- 데이터셋 로드하기
- 라벨 분포 확인하기
- 전처리하기
- 입력과 출력 나누기
- 데이터 미리보기
- one-hot 인코딩하기
- 일반화하기
- 네트워크 구성하기
- 모델 학습시키기
이미지 증강기법 이용해보기
- 학습 데이터 증강하기
train_image_datagen = ImageDataGenerator(
rescale=1./255, # 일반화
rotation_range=10, # 랜덤하게 이미지를 회전 (단위: 도, 0-180)
zoom_range=0.1, # 랜덤하게 이미지 확대 (%)
width_shift_range=0.1, # 랜덤하게 이미지를 수평으로 이동 (%)
height_shift_range=0.1, # 랜덤하게 이미지를 수직으로 이동 (%)
)
train_datagen = train_image_datagen.flow(
x=x_train,
y=y_train,
batch_size=256,
shuffle=True
)- 검증 데이터 일반화하기
test_image_datagen = ImageDataGenerator(
rescale=1./255
)
test_datagen = test_image_datagen.flow(
x=x_test,
y=y_test,
batch_size=256,
shuffle=False
)- 이미지 확인하기
- 네트워크 구성하기
- 모델 학습시키기
전이학습 실습해보기
- 데이터셋 다운로드
- 필요한 패키지 임포트하기
- 전처리하기 - 폴더에서 직접 데이터 가져와서 증강기법까지 써보기
train_datagen = ImageDataGenerator(
rescale=1./255, # 일반화
rotation_range=10, # 랜덤하게 이미지를 회전 (단위: 도, 0-180)
zoom_range=0.1, # 랜덤하게 이미지 확대 (%)
width_shift_range=0.1, # 랜덤하게 이미지를 수평으로 이동 (%)
height_shift_range=0.1, # 랜덤하게 이미지를 수직으로 이동 (%)
horizontal_flip=True # 랜덤하게 이미지를 수평으로 뒤집기
)
test_datagen = ImageDataGenerator(
rescale=1./255 # 일반화
)
train_gen = train_datagen.flow_from_directory(
'fruits-360/Training',
target_size=(224, 224), # (height, width)
batch_size=32,
seed=2021,
class_mode='categorical',
shuffle=True
)
test_gen = test_datagen.flow_from_directory(
'fruits-360/Test',
target_size=(224, 224), # (height, width)
batch_size=32,
seed=2021,
class_mode='categorical',
shuffle=False
)- 데이터 확인하기
- 전이학습 - 모델 가져와서 수정하기
from tensorflow.keras.applications.inception_v3 import InceptionV3
input = Input(shape=(224, 224, 3))
base_model = InceptionV3(weights='imagenet', include_top=False, input_tensor=input, pooling='max')
x = base_model.output
x = Dropout(rate=0.25)(x)
x = Dense(256, activation='relu')(x)
output = Dense(131, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=output)
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.001), metrics=['acc'])- 모델 학습시키기 ** ModelCheckpoint로 정확도 높은 모델 저장
from tensorflow.keras.callbacks import ModelCheckpoint
history = model.fit(
train_gen,
validation_data=test_gen, # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=20, # epochs 복수형으로 쓰기!
callbacks=[
ModelCheckpoint('model.h5', monitor='val_acc', verbose=1, save_best_only=True)
]
)- 학습된 모델 로딩하기
from tensorflow.keras.models import load_model
model = load_model('model.h5')- 결과 확인하기
test_imgs, test_labels = test_gen.__getitem__(100)
y_pred = model.predict(test_imgs)
classes = dict((v, k) for k, v in test_gen.class_indices.items())
fig, axes = plt.subplots(4, 8, figsize=(20, 12))
for img, test_label, pred_label, ax in zip(test_imgs, test_labels, y_pred, axes.flatten()):
test_label = classes[np.argmax(test_label)]
pred_label = classes[np.argmax(pred_label)]
ax.set_title('GT:%s\nPR:%s' % (test_label, pred_label))
ax.imshow(img)
4주차까지 완강하며 머신러닝의 기본 개념과 사용방법을 단계별로 공부해 보았다.