※ 들어가기 앞서 | 영어로 된 용어를 사용하길 권장하는 이유
- 구글, Stackoverflow 등의 사이트에서 영어를 많이 씀
- 의사소통시 영어로 소통해야 의사소통 오류가 적음
- 외국인 엔지니어와의 의사소통
머신러닝이란?
알고리즘 - 수학과 컴퓨터 과학, 언어학 또는 관련 분야에서 어떠한 문제를 해결하기 위해 정해진 일련의 절차나 방법을 공식화한 형태로 표현한 것, 계산을 실행하기 위한 단계적 절차 - 위키피디아
머신 러닝 (Machine Learning, ML) - 기계 학습 또는 머신 러닝은 경험을 통해 자동으로 개선하는 컴퓨터 알고리즘의 연구이다. 인공지능의 한 분야로 간주된다. 컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야이다. 가령, 기계 학습을 통해서 수신한 이메일이 스팸인지 아닌지를 구분할 수 있도록 훈련할 수 있다. 위키백과
딥 러닝 - 심층 학습 또는 딥 러닝은 여러 비선형 변환기법의 조합을 통해 높은 수준의 추상화를 시도하는 기계 학습 알고리즘의 집합으로 정의되며, 큰 틀에서 사람의 사고방식을 컴퓨터에게 가르치는 기계학습의 한 분야라고 이야기할 수 있다. 위키백과
머신러닝 - 회귀와 분류
- 회귀 (Regression)
- ex)사진으로 나이 예측(회귀)
- 모든 문제를 풀기 위해서는 먼저 입력값(Input)과 출력값(Output)을 정의해야 합니다. 이 문제에서 입력값은 [얼굴 사진]이 되고 출력값은 [예측한 나이]가 됩니다. 이 때 출력값인 나이를 소수점(float)로 표현하여 아래와 같이 표현하도록 할 수 있습니다.
- 나이의 값은 연속적이죠. 예를들어 1살, 2살, 3살, ..., 15살, 16살, ..., 89살, 90살... 이렇게 계속해서 나열할 수 있습니다. 이런 식으로 출력값이 연속적인 소수점으로 예측하게 하도록 푸는 방법을 회귀라고 합니다.
- ex)사진으로 나이 예측(회귀)

- 분류 (Classification)
- ex) 시험 전날 공부한 시간을 기반으로 해당 과목의 이수 여부(Pass or fail)를 예측
- 입력값은 [공부한 시간] 그리고 출력값은 [이수 여부] 이다. 이수 여부를 0, 1 이라는 이진 클래스(Binary class)로 나눌 수 있다.
- ex2) 시험 전날 공부한 시간을 기반으로 해당 과목의 성적(A, B, C, D, F)을 예측
- 클래스를 5개의 클래스로 나누고 이 방법을 다중 분류(Multi-class classification, Multi-label classification)라고 부른다.
- ex) 시험 전날 공부한 시간을 기반으로 해당 과목의 이수 여부(Pass or fail)를 예측


- 회귀와 분류 모두 가능한 문제
- ex) 사진으로 나이 예측
- 회귀 방식으로 풀 수도 있지만, 나이 범위에 따른 클래스로 나누어서 다중 분류 문제로 바꾸어서 풀 수 있다.
- ex) 사진으로 나이 예측


지도 학습/비지도 학습/강화 학습

지도 학습(Supervised learning): 정답을 알려주면서 학습시키는 방법

우리가 위에서 배웠던 회귀와 분류 문제가 대표적인 지도 학습에 속합니다. 지도 학습은 기계에게 입력값과 출력값을 전부 보여주면서 학습시키죠. 우리는 이미 정답을 알고 있기 때문에 정답을 잘 맞추었는지 아닌지를 쉽게 파악할 수 있습니다. 대신 정답(출력값)이 없으면 이 방법으로 학습시킬 수 없습니다.
여러분이 회사에서 머신러닝 엔지니어로 근무한다면 회사에서 필요로 하는 문제를 풀기 위해 많은 데이터를 필요로 할 겁니다. 근데 대부분 회사에는 데이터가 없는 경우가 많죠. 혹은 입력값에 해당하는 데이터는 있어도 출력값(정답)에 해당하는 데이터가 없는 경우가 비일비재합니다. 따라서 입력값에 정답을 하나씩 입력해주는 작업을 하게 되는 경우가 있는데 그 과정을 노가다 라벨링(Labeling, 레이블링) 또는 어노테이션(Annotation)이라고 합니다.
비지도 학습 (Unsupervised learning): 정답을 알려주지 않고 군집화(Clustering)하는 방법

비지도 학습은 그룹핑 알고리즘(Grouping algorithm)의 성격을 띄고 있습니다. 예를 들어 음악을 분석하여 장르를 구분하는 문제를 푼다고 가정해봅시다.
음원 파일을 분석하여 장르를 팝, 락, 클래식, 댄스로 나누는 문제우리가 가지고 있는 데이터에 입력값(음원파일)과 출력값(장르) 둘 다 존재한다면 우리는 지도 학습으로 이 문제를 풀 수 있지만 출력값에 해당하는 장르 데이터가 없을 때 비지도 학습 방법을 사용합니다. 비지도 학습 방법은 라벨(Label 또는 Class)이 없는 데이터를 가지고 문제를 풀어야 할 때 큰 힘을 발휘하죠! 음악 장르를 구분하는 문제를 비지도 학습을 사용해서 풀라고 시키면 아래와 같은 뉘앙스가 됩니다.
우리에게는 수 백만개의 음원 파일이 있는데, 각 음원 파일에 대한 장르 데이터는 없어.
그러니까 기계에게 음원 파일을 들려주고 알아서 비슷한 것끼리 분류하게 해보자!
비지도 학습의 종류 (참고)

- 군집 (Clustering)
- K-평균 (K-Means)
- 계측 군집 분석(HCA, Hierarchical Cluster Analysis)
- 기댓값 최대화 (Expectation Maximization)
- 시각화(Visualization)와 차원 축소(Dimensionality Reduction)
- 주성분 분석(PCA, Principal Component Analysis)
- 커널 PCA(Kernel PCA)
- 지역적 선형 임베딩(LLE, Locally-Linear Embedding)
- t-SNE(t-distributed Stochastic Neighbor Embedding)
- 연관 규칙 학습(Association Rule Learning)
- 어프라이어리(Apriori)
- 이클렛(Eclat)
강화 학습(Reinforcement learning): 주어진 데이터없이 실행과 오류를 반복하면서 학습하는 방법 (알파고를 탄생시킨 머신러닝 방법!!)

행동 심리학에서 나온 이론으로 분류할 수 있는 데이터가 존재하지 않거나, 데이터가 있어도 정답이 따로 정해져 있지 않고, 자신이 한 행동에 대해 보상(Reward)를 받으며 학습하는 것을 말합니다.
- 강화학습의 개념
- 에이전트(Agent)
- 환경(Environment)
- 상태(State)
- 행동(Action)
- 보상(Reward)
게임을 예로 들면 게임의 규칙을 따로 입력하지 않고 자신(Agent)이 게임 환경(Environment)에서 현재 상태(State)에서 높은 점수(Reward)를 얻는 방법을 찾아가며 행동(Action)하는 학습 방법으로 특정 학습 횟수를 초과하면 높은 점수(Reward)를 획득할 수 있는 전략이 형성되게 됩니다. 단, 행동(Action)을 위한 행동 목록(방향키, 버튼)등은 사전에 정의가 되어야 합니다.
[DEVSISTERS 머신러닝 팀] 딥러닝과 강화학습으로 학습한 쿠키런 AI 사진

만약 이것을 지도 학습(Supervised Learning)의 분류(Classification)를 통해 학습을 한다고 가정하면 모든 상황에 대해 어떠한 행동을 해야 하는지 모든 상황을 예측하고 답을 설정해야 하기 때문에 엄청난 데이터가 필요합니다. 예를 들어 바둑을 학습한다고 했을 때, 지도 학습(Supervised Learning)의 분류(Classification)를 이용해 학습하는 경우 아래와 같은 개수의 데이터가 필요해지게 됩니다.
바둑의 경우의 수
208168199381979984699478633344862770286522453884530548425639456820927419612738015378525648451698519643907259916015628128546089888314427129715319317557736620397247064840935강화 학습(Reinforcement learning)은 이전부터 존재했던 학습법이지만 이전에 알고리즘은 실생활에 적용할 수 있을 만큼 좋은 결과를 내지 못했습니다. 하지만 딥러닝의 등장 이후 강화 학습에 신경망을 적용하면서부터 바둑이나 자율주행차와 같은 복잡한 문제에 적용할 수 있게 되었습니다.
선형 회귀 (Linear Regression)
- 선형 회귀와 가설, 손실 함수 Hypothesis & Cost function (Loss function)
가설 - 데이터를 기반으로 임의로 만든 직선

우리가 만든 임의의 직선(가설)과 점(정답)의 거리가 가까워지도록 해야합니다. (=mean squared error)

여기서 H(x)는 우리가 가정한 직선이고 y 는 정답 포인트라고 했을 때 H(x)와 y의 거리(또는 차의 절대값)가 최소가 되어야 이 모델이 잘 학습되었다고 말할 수 있을겁니다.
여기서 우리가 임의로 만든 직선 H(x)를 가설(Hypothesis)이라고 하고 Cost를 손실 함수(Cost or Loss function)라고 합니다.
※ 실무에서 사용하는 머신러닝 모델은 1차 함수보다 더 높은 고차원 함수이지만 원리는 똑같습니다. 우리는 데이터를 보고 "어떤 함수에 비슷한 모양일 것이다"라고 가설을 세우고 그에 맞는 손실 함수를 정의합니다. 우리가 하는 일은 여기서 끝이고 기계는 우리가 정의한 손실 함수를 보고 우리의 가설에 맞출 수 있도록 열심히 계산하는 일을 한답니다. 그래서 기계학습(머신러닝)이라는 이름이 붙게 된 것이지요.
- 다중 선형 회귀(Multi-variable linear regression)
선형 회귀와 똑같지만 입력 변수가 여러개

경사 하강법 (Gradient descent method)
경사 하강법이란?

손실 함수가 위와 같은 모양을 가지고 있다고 가정해보죠.
우리의 목표는 손실 함수를 최소화(Optimize)하는 것입니다. 손실 함수를 최소화하는 방법은 이 그래프를 따라 점점 아래로 내려가야하죠.
컴퓨터는 사람처럼 수식을 풀 수 없기때문에 경사 하강법이라는 방법을 써서 점진적으로 문제를 풀어갑니다. 처음에 랜덤으로 한 점으로부터 시작합니다. 좌우로 조금씩 그리고 한번씩 움직이면서 이전 값보다 작아지는지를 관찰합니다. 한칸씩 전진하는 단위를 Learning rate라고 부르죠. 그리고 그래프의 최소점에 도달하게 되면 학습을 종료하면 되겠죠.

Learning Rate
우리가 만든 머신러닝 모델이 학습을 잘하기 위해서는 적당한 Learning rate를 찾는 노가다가 필수적입니다!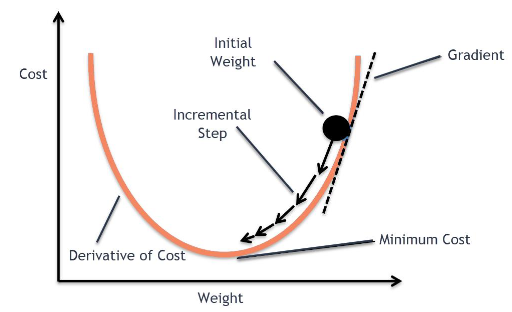
위의 그래프에서 만약 Learning rate가 작다면 어떻게 될까요? 초기 위치로부터 최소점을 찾는데까지 많은 시간이 걸릴 것입니다. 그리고 이 것은 학습하는데, 즉 최소값에 수렴하기까지 많은 시간이 걸린다는 것을 뜻합니다.
반대로 만약 Learning rate가 지나치게 크다면요? 우리가 찾으려는 최소값을 지나치고 검은 점은 계속 진동하다가 최악의 경우에는 발산하게 될 수도 있습니다. 이런 상황을 Overshooting이라고 부릅니다.
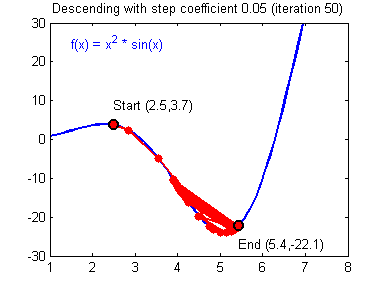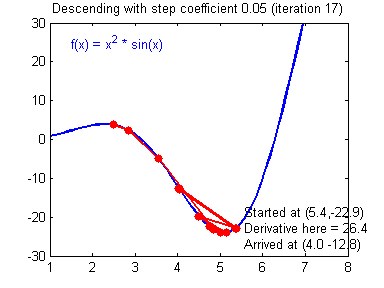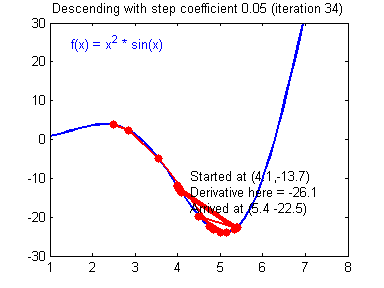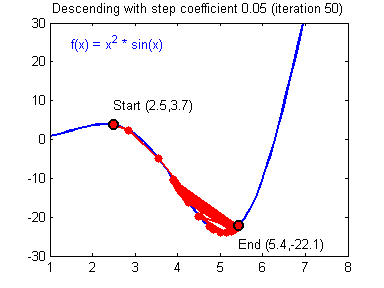
※ local cost minimum, 실제로 손실 함수를 그릴 수 있을까?
간단한 선형 회귀 문제의 경우는 그래프를 그릴 수는 있지만 복잡한 가설을 세울 경우에는 사람이 그릴 수도 없고 상상할 수 없는 형태가 됩니다. 예를 들어 간단하게 아래와 같은 그래프를 상상할 수 있겠군요.

우리의 목표는 이 손실 함수의 최소점인 Global cost minimum을 찾는 것입니다. 그런데 우리가 한 칸씩 움직이는 스텝(Learning rate)를 잘못 설정할 경우 Local cost minimum에 빠질 가능성이 높습니다. Cost가 높다는 얘기는 우리가 만든 모델의 정확도가 낮다는 말과 같지요. 따라서 우리는 최대한 Global minimum을 찾기 위해 좋은 가설과 좋은 손실 함수를 만들어서 기계가 잘 학습할 수 있도록 만들어야하고 그것이 바로 머신러닝 엔지니어의 핵심 역할입니다!
데이터셋 분할
학습/검증/테스트 데이터

- Training set (학습 데이터셋, 트레이닝셋) = 교과서
- 머신러닝 모델을 학습시키는 용도로 사용합니다. 전체 데이터셋의 약 80% 정도를 차지합니다.
- Validation set (검증 데이터셋, 밸리데이션셋) = 모의고사
- 머신러닝 모델의 성능을 검증하고 튜닝하는 지표의 용도로 사용합니다. 이 데이터는 정답 라벨이 있고, 학습 단계에서 사용하기는 하지만, 모델에게 데이터를 직접 보여주지는 않으므로 모델의 성능에 영향을 미치지는 않습니다.
- 손실 함수, Optimizer 등을 바꾸면서 모델을 검증하는 용도로 사용합니다.
- 전체 데이터셋의 약 20% 정도를 차지합니다.
- Test set (평가 데이터셋, 테스트셋) = 수능
- 정답 라벨이 없는 실제 환경에서의 평가 데이터셋입니다. 검증 데이터셋으로 평가된 모델이 아무리 정확도가 높더라도 사용자가 사용하는 제품에서 제대로 동작하지 않는다면 소용이 없겠죠?